What is MUD?
MUD is a framework for ambitious onchain applications. It reduces the complexity of building Ethereum (opens in a new tab) apps with a tightly integrated software stack. It's open source (opens in a new tab) and free to use (opens in a new tab).
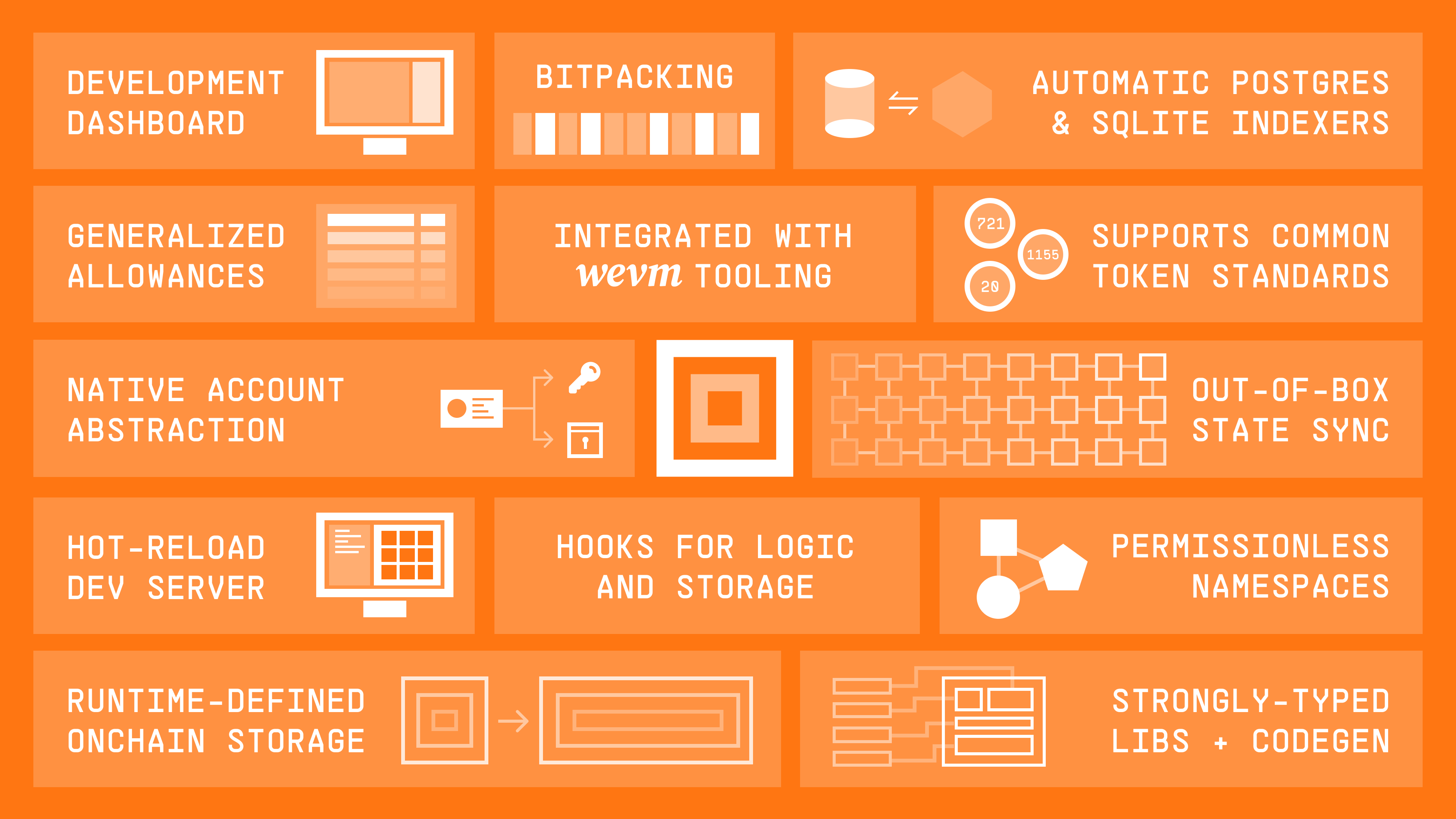
Why MUD?
Writing smart contracts is only a small part of building user-friendly EVM apps. Your frontend needs get data from the chain. You've kept your onchain logic simple to save users gas, but now getting data from the RPC is tricky and slow. So you spin up an indexer, write event handlers, and teach your frontend how to talk to another backend. Complicated, right?
MUD provides much of this out of the box. It uses a familiar data model with tables and fields, built on a standardized storage protocol. This lets us provide you with an automatic indexer, no code is necessary to use it. And because it's all standardized, our client libraries already know how to get your app's onchain state and keep your frontend in sync with the chain.
MUD apps are autonomous worlds (opens in a new tab), infinitely extendable by default. They come with access control, upgradability, hooks, plugins, and a suite of great developer tools.
Give it a try and let us know (opens in a new tab) what you think!
How it started
MUD evolved out of our experiences building onchain games like Dark Forest (opens in a new tab) and zkDungeon. We identified many difficulties along the way: coupling of state and logic in smart contracts makes upgrading logic difficult, lack of synchrony between the chain and client can lead to inconsistencies in game state, irregularities with access controls pose problems for would-be third-party developers attempting to create their own plugins and clients. This revealed the need for a framework and a protocol to handle the inevitable complexity of game code, and to counteract the developer-unfriendly patterns inherent in the way smart contracts are traditionally written. We built MUD with solutions to these problems in mind.
The projects built with MUD speak for themselves: some of the most complex applications on Ethereum have been built with the framework in record time. OPCraft (opens in a new tab), a fully onchain voxel world, was built by Lattice in 1.5 months. While it didn't have the security and auditing requirement of financial applications, it handled more transaction throughput than most apps on Mainnet ever did in their lifetime: in 10 days, OPCraft players made 3.5 million transactions, filling the MUD onchain database with billions of gas worth of storage; with the client seamlessly handling synchronizing that state back. OPCraft used MUD without any additional tricks: large onchain applications with minimal client headaches can be yours too!
MUD is maximally onchain: the entire application state lives in the EVM, and the only requirement for clients and frontends is an Ethereum Node. You can use all MUD libraries together as a framework and get super-powers, or only pick the parts you like. It's up to you!